위코드 기간중에 진행했던 프로젝트 중에서 데이터 로딩 속도 확보를 위해서 Redis를 통한 캐싱을 적용했던 적이 있다.
상품 데이터 로딩 속도가 너무 느려서 로딩 속도를 빠르게 해 볼 생각만 가지고 캐싱을 적용해봤던 거라서 어떤 상황에서 캐싱을 적용하면 좋을지 정확하게는 모르겠다.
일단은 전에 적용했던 방식을 간단하게 정리해서 혹시라도 나중에 사용할 일이 있으면 참고하려고 한다.
캐싱이란
- 내가 전부터 알던 캐싱이라는 단어는 CPU의 캐시 메모리를 기반으로 한다. 사용이 잦은 데이터의 경우 매번 기억장치 간 이동으로 인한 시간 손실을 피하기 위해서 CPU 내부의 크기는 작지만 접근 속도가 압도적으로 빠른 캐시 메모리에 저장해 놓고 사용하는 방식
- WAS에서의 캐싱 또한 비슷한 개념으로 이해했다. 특히나 데이터 로딩 속도 문제로 인해서 캐싱을 적용하고자 마음먹었었기에 자주 사용될 데이터를 사용하기 좋게 구성한 후에 캐싱해 놓고 해당 캐싱 데이터를 사용하는 방향으로 사용했다.
- 즉, CPU의 캐시 메모리의 경우를 통해서 WAS의 캐싱을 이해하는 게 괜찮은 접근 방식으로 보인다. 자주 사용하는 데이터를 따로 저장해 놓고 해당 데이터를 사용 할 필요가 있을 때에는 바로 사용하는 일련의 과정을 캐싱이라고 이해하며 된다.
Redis란?
- Redis는 데이터베이스의 하나인데, 일반적인 RDBMS(관계형 데이터베이스)들과는 다르다. No-SQL이라고 말하는 비관계형 베이터 베이스에 속하는 데이터베이스이다.
- No-SQL에도 여러 분류에 따라서 데이터베이스를 나눌 수 있지만 Redis는 그중에서도 Key-Value Type 데이터베이스에 속한다.
- 저장할 때, Key를 지정해서 Value를 저장하게되며 저장된 데이터를 사용할 때에는 지정된 Key를 통해서 저장된 데이터를 사용하게 된다.
- 더 자세한 Redis에 대해서는 따로 포스팅해보는 것도 좋아보인다. ( 내용이 조금 되는 편)
Django에서 Redis를 사용하려면?
- Mac 기준으로 진행한다.
brew install redis- brew 패키지 관리자를 통해서 간단하게 설치 가능하다.

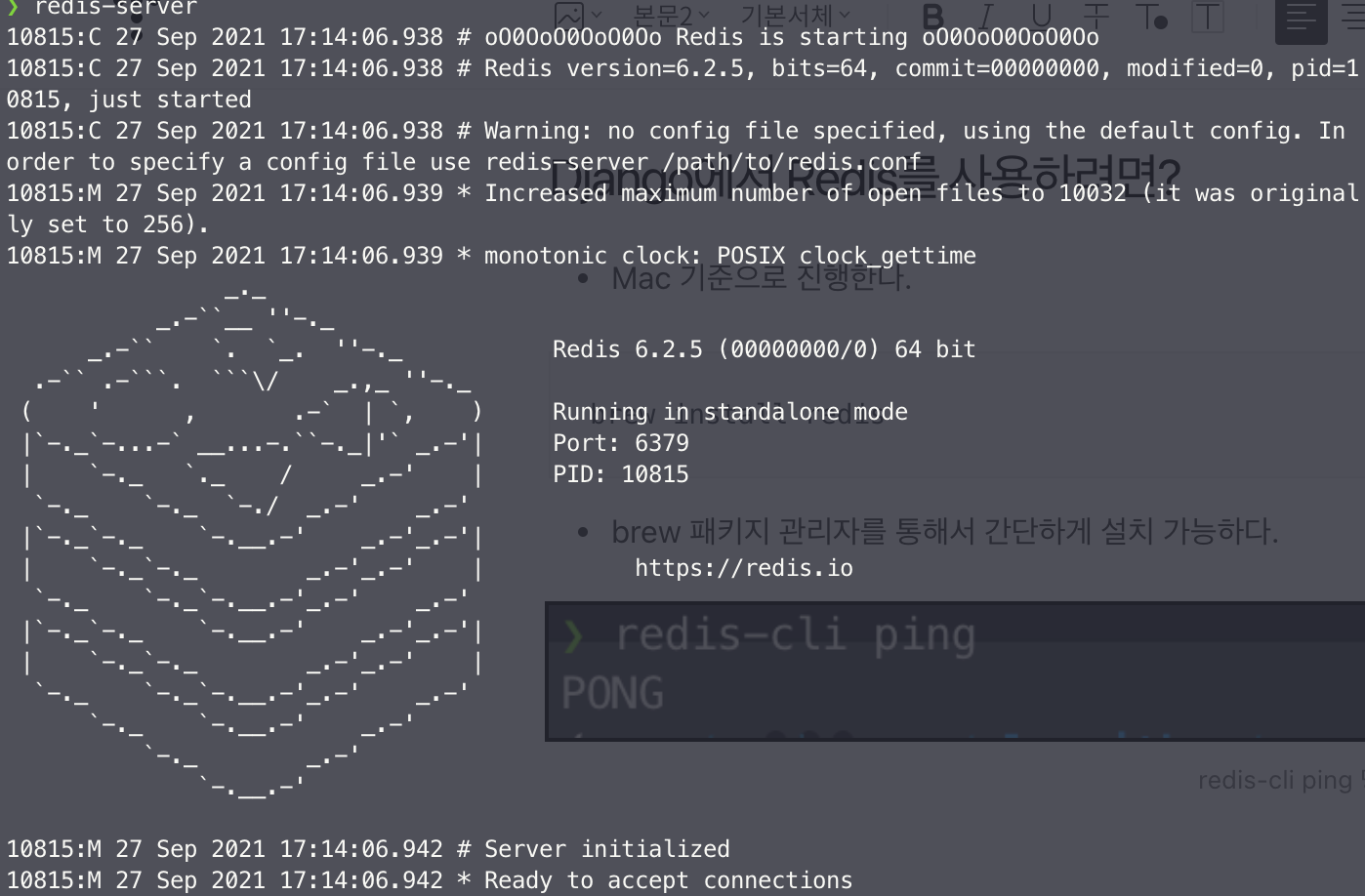
- Redis 설치가 완료되면 Django와 Redis 사이에 위치해 줄 미들웨어가 있어야한다. pip를 통해서 django-redis를 설치해준다.
pip / pip3 install django-redis
- 문제없이 미들웨어 설치가 완료되면 Redis를 사용할 Django 프로젝트의 setting파일에 옵션을 추가해주어야 한다.
...
# Redis RAM cache setting
CACHE = {
"default" : {
"BACKEND" : "django_redis.cache.RedisCache",
"LOCATION" : "redis://127.0.0.1:6379/1",
"OPTION" : {
"CLIENT_CLASS" : "django_redis.client.DefaultClient",
}
}
}
...- 프로젝트의 setting파일에 옵션을 반영했다면, 이제 실질적으로 캐싱 기능을 사용할 API들이 작성되어 있는 앱의 views 파일에 Redis에 저장하거나, 불러오는 코드를 추가해주면 사용 준비는 완료된다.
...
from django.core.cache import cache
...
class CaseView(View):
def post(self, request):
try:
...
if flag:
data = Case.objects.all()
temp_data = [ {
'name' : case.name,
'code' : case.code
} for case in data ]
cache.set('all_cases', temp_data) # "all_cases" 를 Key로, temp_data 딕셔너리 리스트를 Value로 저장
...
def get(self, request):
...
all_cases = cache.get('all_cases') # "all_cases" Key를 통해서 저장된 Value에 접근
if not all_cases:
temp_data = [ {
'name' : case.name,
'code' : case.code
} for case in data ]
cache.set('all_cases', temp_data)
all_cases = temp_data
...
...
Redis를 적용 전후 비교
- 사전에 약 2000개의 단순한 데이터를 만들어 놓은 상태에서 전체 데이터를 조회 한 후에 딕셔너리 리스트를 구성하는 API를 통해서 작동 시간을 비교해보았다.

- 2000개 정도의 그리 크지 않은 데이터, 단순한 ORM, 복잡하지 않은 데이터 프로세싱을 기반으로 진행한 테스트이기에 엄청난 향상이 있지는 않지만 약 10ms 정도의 속도가 개선됨을 확인 할 수 있다.
결론 및 더 알아볼 점
- 만약 캐싱되어 있는 데이터가 최신화된 데이터를 반영하지 못한다면 이는 무의미한 작업(DB와 캐싱 데이터가 서로 다른 상황)이 된다. 캐싱 대상이 된 데이터에 어떤 변조가 이루어 졌다면 반드시 캐싱 데이터에도 최신화가 이루어져야 한다.
- Delete Method 관련 테스트 API를 만들어 놓지 않아서 캐싱된 데이터를 삭제하는 것은 테스트해보지 못함
- 테스트 프로젝트에서는 Get Method에서는 조건부 저장을 진행하고 Post Method에서는 무조건 저장을 진행했는데 Key를 삭제하지 않고 계속 같은 Key를 사용하고 있는 상황이다. 이런 상황이 혹시 어떤 문제를 야기할 수 있지는 않은지 확인해볼 필요가 있다.
- Redis를 또 다른 어떤 기능에 적용해 볼 수 있을지 생각해보는 것도 좋아보인다.
'프로그래밍 > Python' 카테고리의 다른 글
| DRF - Serializer (0) | 2021.12.22 |
|---|---|
| Python - 예외처리 (0) | 2021.11.18 |
| Django - 로깅 (0) | 2021.09.11 |
| Conda 기본 (0) | 2020.07.29 |
| Python - Class (0) | 2020.07.23 |



